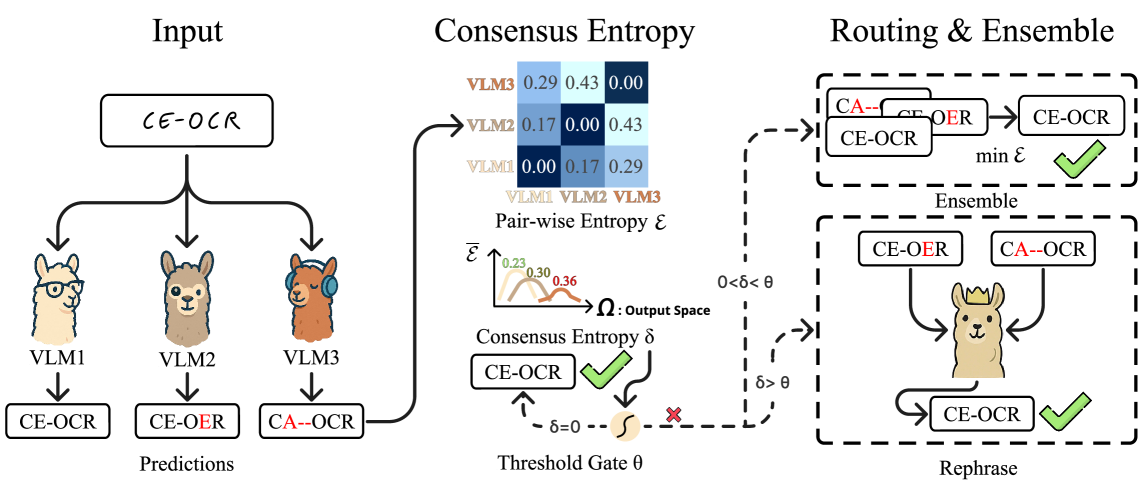
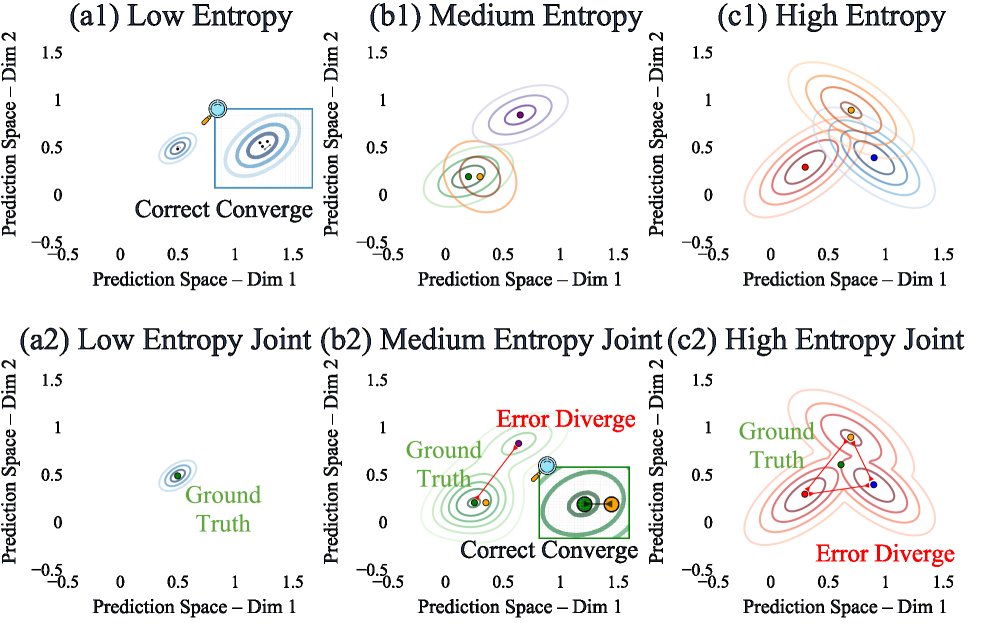
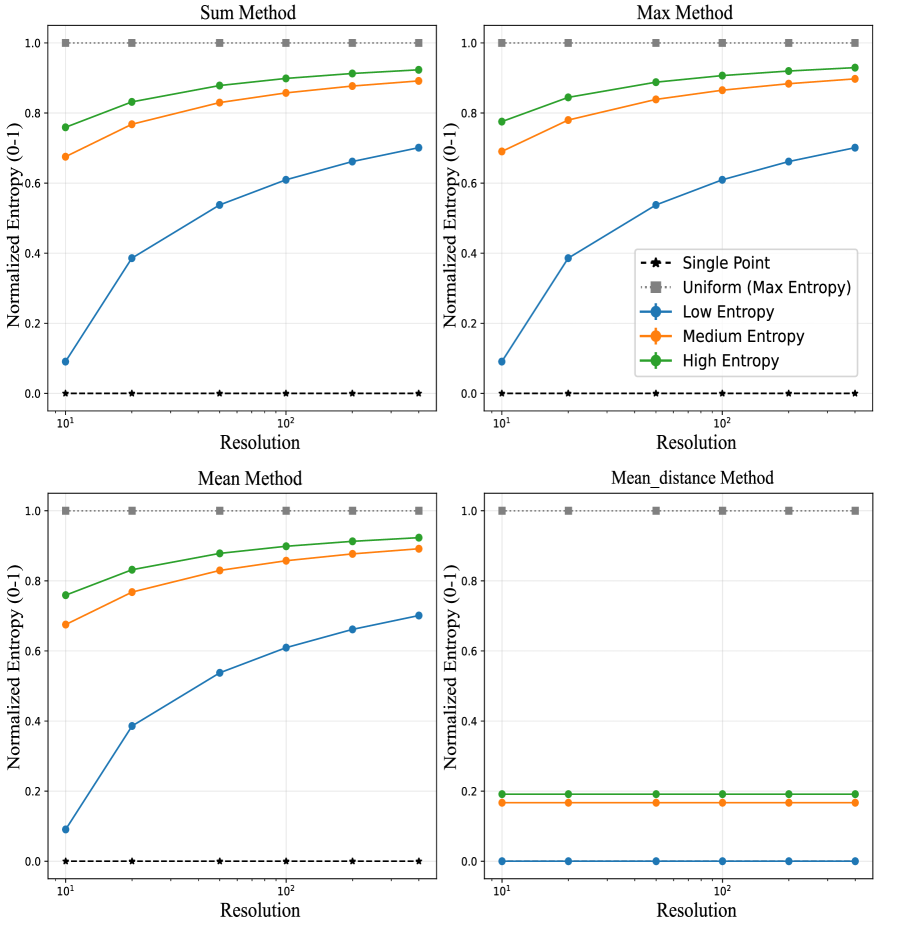
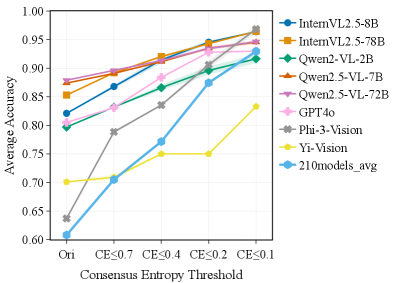
OCR verification: CE vs. VLM-as-Judge
Consensus Entropy is computed directly from VLM predictions and substantially improves F1 over prompting a VLM to judge OCR correctness.
| Reference VLM | VLM-as-Judge F1 | CE F1 | Relative Gain |
|---|---|---|---|
| GPT-4o | 40.0 | 48.0 | +20.0% |
| Qwen2-VL-7B | 36.1 | 51.3 | +42.1% |
| Qwen2-VL-72B | 39.8 | 51.0 | +28.1% |
CE-Ensemble gains with more participating models
Across 3-5 model ensembles on OCRBench, CE-based output selection consistently improves over both the weakest and strongest individual model in most cases.
| # Models | Avg. gain over weakest | Avg. gain over best | Positive cases over best | Positive cases over average |
|---|---|---|---|---|
| 3 | 50.2 | 4.2 | 66.2% | 94.7% |
| 4 | 67.5 | 12.7 | 82.2% | 100.0% |
| 5 | 78.3 | 17.8 | 91.1% | 100.0% |
CE-OCR on OCRBench-V2
With GPT-4o rephrasing for routed samples, CE-OCR improves over CE-Ensemble and the best single model on most OCRBench-V2 categories.
| Method | English OCR | Math | Element Parsing | Chinese Overall |
|---|---|---|---|---|
| Best single model | 65.6 | 47.7 | 32.6 | 44.2 |
| CE-Ensemble | 67.2 | 50.1 | 34.0 | 45.7 |
| CE-OCR | 71.6 | 53.1 | 33.8 | 48.0 |